Information on output-file organization
The MF4 decoders take a set of input-files (containing encoded records), a database (containing rules[1]), and produce a set of output-files (containing decoded signals).
This section describes the mapping between the input-files and the resulting output-files.
Records from the input-files are read one-by-one, matched with a rule, decoded and placed in an output-file. The selection of output-file is based on the following criteria:
DEVICE: The ID of the physical device that captured the recordRULE: The rule used to decode the record into a set of signalsDATE: The timestamp of the record
Given above criteria, below figure illustrates how a set of input-files generates a partitioned and nested structure of decoded output-files.

Note
Files stored under the rule directory level share the same (data) schema[2] and can be parsed as if they were one file (supported by some tools).
Specifically, the output-file paths are constructed from the following parts:
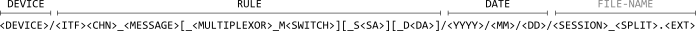
DEVICE: Device (ID)[3] (e.g.AABBCCDD)ITF: Bus interface (e.g.CANorLIN)CHN: Bus channel (e.g.1)MESSAGE: Name of message in rule (e.g.VehicleSpeed)MULTIPLEXOR: Name of active signal multiplexor in rule (if any, e.g.Service)SWITCH: From value of multiplexor switch (if multiplexor, e.g.0B)SA: Node source-address (if any, e.g.F1)DA: Node destination-address (if any, e.g.F2)YYYY: Year (e.g.2020)MM: Month (e.g.01)DD: Day of month (e.g.01)SESSION: Session counter value[4] (e.g.00000001)SPLIT: Split counter value[4] (e.g.00000001)EXT: Specific decoder extension (e.g.csv)
Note
The structure of the FILE-NAME ensures that output-files never collide
Note
The [_<MULTIPLEXOR>_M<SWITCH>] block can be repeated if the rule uses nested multiplexing
Output concatenation
When output concatenation is enabled, the decoders attempt to concatenate output-files[5] mapped to the same output-directory. Concatenation is only possible as long as input-files are consecutive[6].
Note
Output concatenation can in some cases reduce the number of output-files considerably.
Example
A set of input-files generate the following output-files without and with output concatenation:
AABBCCDD/CAN1_GnssTime/2020/01/01/00000001_00000001.ext
AABBCCDD/CAN1_GnssTime/2020/01/01/00000001_00000002.ext
AABBCCDD/CAN1_GnssTime/2020/01/01/00000001_00000003.ext
AABBCCDD/CAN1_GnssTime/2020/01/01/00000002_00000001.ext <- Not consecutive
AABBCCDD/CAN1_GnssTime/2020/01/01/00000002_00000002.ext
AABBCCDD/CAN1_GnssTime/2020/01/02/00000003_00000001.ext <- Not consecutive
AABBCCDD/CAN1_GnssTime/2020/01/02/00000003_00000002.ext
AABBCCDD/CAN1_GnssTime/2020/01/01/00000001_00000001.ext
AABBCCDD/CAN1_GnssTime/2020/01/01/00000002_00000001.ext
AABBCCDD/CAN1_GnssTime/2020/01/02/00000003_00000001.ext